ChatGPTの高度な機能、例えばコードのデバッグ、エッセイの執筆、ジョークの作成などが、その人気をもたらしています。その能力にもかかわらず、テキストへの支援に限定されていましたが、それは変わろうとしています。
火曜日、OpenAIはGPT-4を発表しました。GPT-4は、テキストと画像の両方の入力を受け付け、テキストを出力します。
GPT-3.5とGPT-4の違いは、日常会話では「微妙な」ものです。しかし、新しいモデルは信頼性、創造性、さらには知能の面でも非常に能力が向上しています。
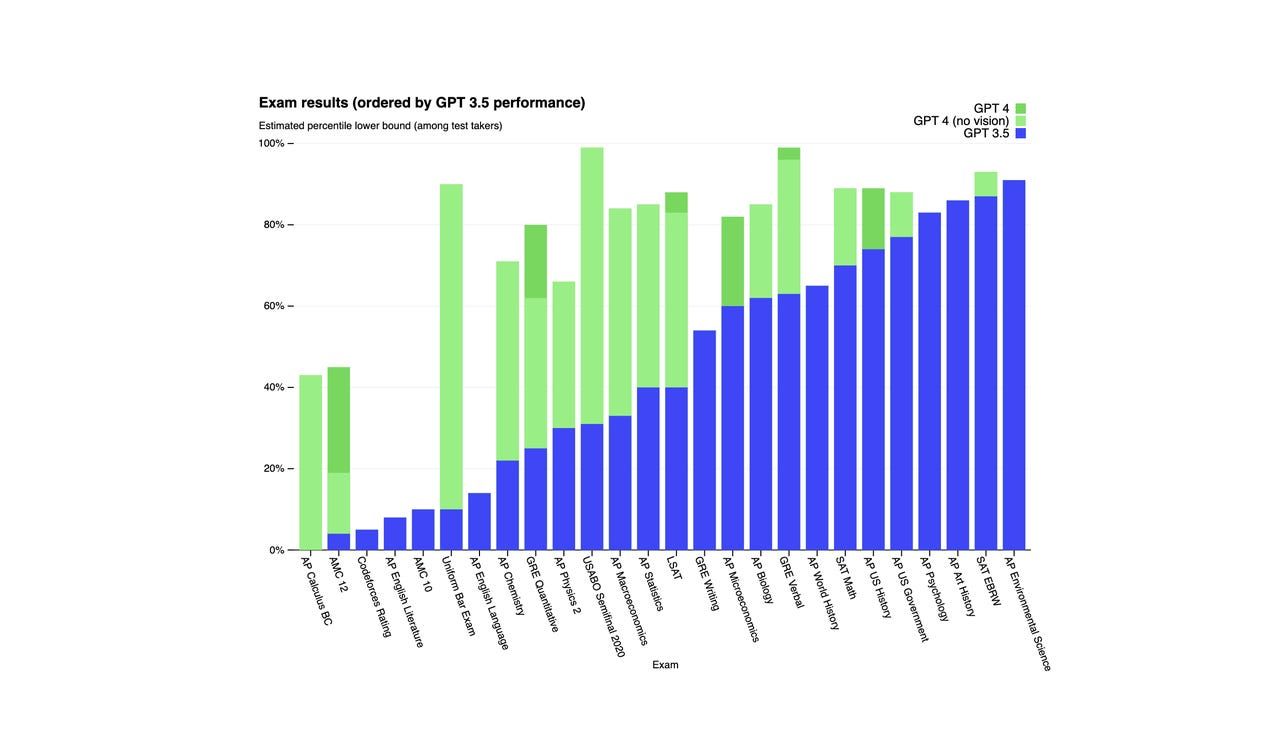
OpenAIによると、GPT-4はシミュレートされた司法試験のトップ10%に入るスコアを獲得しました。一方、GPT-3.5はボトム10%程度のスコアでした。以下のグラフで見られるように、GPT-4はさまざまなベンチマークテストでもGPT-3.5を上回る成績を収めました。

文脈について、ChatGPTは、3.5シリーズのモデルから微調整された言語モデルを利用しており、チャットボットはテキストの出力に制限されています。
OpenAIのGPT-4の発表は、先週マイクロソフトドイツのCTOであるアンドレアス・ブラウン氏の演説に続いて行われました。彼はGPT-4が近日中に登場し、テキストからビデオの生成が可能になると述べました。
"来週、GPT-4を紹介します。マルチモーダルモデルを提供し、完全に異なる可能性を提供します、例えば、ビデオです"、とHeise(ドイツのニュースメディア)の報道によると、Braun氏がイベントで述べました。
GPT-4がマルチモーダルであるにもかかわらず、テキストからビデオを生成するという主張はやや誤りでした。このモデルはまだビデオを生成することができませんが、前のモデルとは大きく異なり、ビジュアル入力を受け入れることができます。
OpenAIが提供した例の1つに、この機能を紹介するためにChatGPTが画像をスキャンして、ユーザーの入力に基づいて写真の何が面白いのかを判別しようとするというものがあります。
他の例には、グラフの画像をアップロードしてGPT-4に計算を依頼したり、ワークシートをアップロードして問題を解決するように依頼することもありました。
また:エッセイ作成のためにChatGPTがあなたをどのように助けるか、5つの方法
OpenAIは、GPT-4のテキスト入力機能をChatGPTおよびAPI経由でリリースする予定です。画像入力機能については、OpenAIが単一のパートナーと協力して開始するまで、もう少し待つ必要があります。
もしテキストからビデオを生成することができないことにがっかりしているなら、心配しないでください。それはすでに完全に新しい概念ではありません。MetaやGoogleのようなテックジャイアンツは既にモデルを開発しています。MetaにはMake-A-Videoがあり、GoogleにはImagen Videoがあります。両者とも、ユーザーの入力からビデオを作成するためにAIを使用しています。